情報検索の技術的な向上のための研究をこれまで進めてきました。今では,インターネットのサーチエンジンで手軽に情報を検索できますが,それ以前は,検索のためには,図書館に行かなくてはなりませんでした。もともと,コンピュータの登場以前に図書館で資料を探すために使われていた仕組みをコンピュータに移すことによって,情報検索システムが実現されたという歴史的な経緯があります。この点で,情報検索は図書館情報学の中核のひとつであり,その技術向上は重要な研究課題となっています。
情報検索の研究が大きく変化したのは,1990年代前半です。インターネット上の情報資源を効果的かつ効率的に探し出すためには,高度な情報検索の技術が要求されます。このため,データベース管理や自然言語処理の専門家などが加わって,学際的な研究プロジェクトが進められるようになりました。それまでの図書館情報学分野における情報検索の対象は,「情報」そのものではなく,図書や論文などの「図書館資料」でした。つまり,情報そのものではなく,それを含んだパッケージである資料に対する検索が探究されていたのです。それが1990年代以降,大きく様変わりしました。
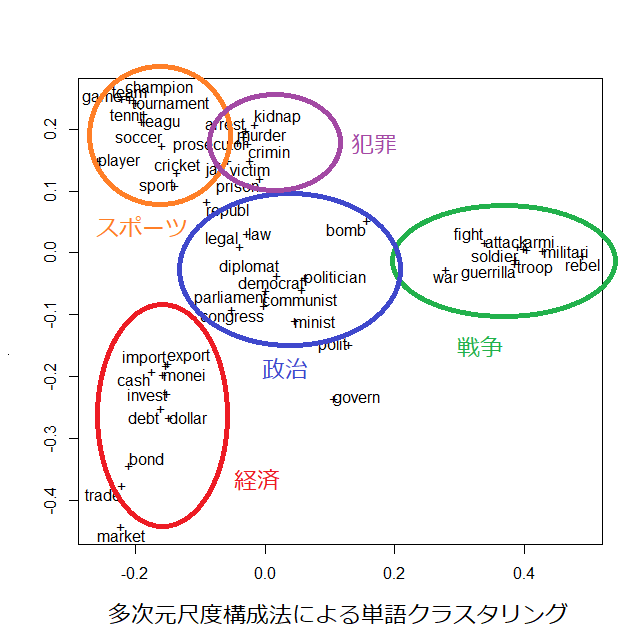
現在では,コンピュータの発達により,資料の「中身」を取り扱えるようになっています。つまり,資料は文章の連続から構成されるテキストであり,そのテキストデータを直接解析できるようになったわけです。この結果,テキストから情報を「掘り出す」ためのテキストマイニングという技術に注目が集まるようになりました。これには情報検索や自然言語処理の技術を活用します。その中で,私は,文書や単語を類似したクラスタ(まとまり)に自動分類する問題に取り組んでいます。例えば,日々,大量のツイートが投稿されていますが,これらを自動分類することにより,世の中で何が話題になっているかを知ることができます。さらには,ある特定のトピックに絞り込んで,それに関する意見や考え方を抽出することも可能です。テキストデータの解析には,そのほかにもさまざまな応用が考えられ,その技術向上により,多くの恩恵がもたらされると考えています。
(2020/12/21)


